
|
Copyright 2001 IEEE. Published in the Proceedings of 13th International Conference on Application-specific Systems, Architectures and Processors (ASAP 2002), p. 185-196, San Jose, California (USA), July 17-19, 2002.
Digit-recurrence division is an algorithm in which the quotient is obtained one digit per iteration. This algorithm has been extensively studied (for additional references see for instance [1]) and provides good tradeoff among latency, area, and power, allows simple exact rounding, and does not introduce overhead on the floating-point multiplier. It has been implemented in many high-performance floating-point units for general-purpose and application-specific processors, such as processors for 3D graphic applications ; some recent examples are described in [2,,,].
The determination of the quotient digit is performed by the quotient-digit selection function. The prevalent method used today for this quotient-digit selection is to use selection constants and implement it by a combinational network having as inputs a truncated redundant residual and a truncated divisor. Because of the delay/complexity of this network, this approach is practical for relatively small radices, mainly radix 4 and possibly up to radix 8. An alternative implementation is based on comparisons of the residual estimate with truncated multiples of the divisor; however, this implementation is rarely used in practice because it requires assimilation of the truncated redundant residual and comparison, so no advantage is obtained with respect to the implementation with selection constants.
Recently [6], a scheme was described that uses the selection function with selection constants but implements it with comparisons 2. Specifically, since the divisor is fixed during all the iterations, the selection constants corresponding to the value of the truncated divisor are preloaded into registers and the quotient-digit selection is performed by comparing the truncated residual with the selection constants. To reduce the delay, the comparisons are implemented by a carry-free subtraction of the selection constants from the redundant residual and then performing a sign detection. From the synthesis we performed we estimate that for radix 4 this results in a delay reduction of about 5% with respect to the direct implementation. In this paper, we propose to utilize this decomposition of the comparison into redundant subtraction and sign detection and to retime the recurrence so that the subtraction is not part of the critical path. We have estimated the resulting delay and obtained an additional 30% reduction. Moreover, we estimate that the area of the three implementations is almost the same.
In the next sections we present the modified algorithm, discuss the timing alternatives for minimal delay, and do and estimation of the delay.
Digit-by-digit radix-r division algorithms compute the final result by performing a suitable number of iterations, each one consisting of the following phases:
Quotient-Digit Selection: based on the value of the current residual
and of the divisor one digit of the quotient is produced. If a redundant digit
set is used for the quotient, estimates of the shifted residual (denoted by
[^y]) and of the divisor ([^d])
can be used, resulting in
|
|
Residual Updating and Quotient Formation: using the digit selected at step
1, the next residual and quotient are produced, as follows:
|
|
The implementation of the recurrence for radix-4 is shown in Figure 1. Note that we present a retimed version in which the quotient-digit selection is placed at the end of the iteration since this constrains the critical path to the most-significant slice, which can be designed for smaller delay. This retiming was used in [7], where it is called model division with prediction, and in [8], to reduce the energy dissipation. The retimed version allows us to speed up the scheme proposed in [6].
Although it is possible to define correct digit selection rules for any radix, the approach is practical only for relatively low radices, such as 2, 4, and 8, because for higher radices the resulting implementation has a large area and delay. For this reason, for higher radices alternative techniques have been studied, such as multistage algorithms and/or prescaling.
The prevalent implementation of the selection function above consists of a combinational network (multilevel network, PLA or ROM) having as inputs the estimate of the residual and of the divisor and producing the quotient digit. For instance, for radix 4 with a quotient digit-set {-2,-1,0,1,2}, 7 bits of [^y] and 3 bits of [^d] are sufficient (see Figure 1). Typically, the selection network is implemented as shown in Figure 2a) and its delay corresponds to about 50% of the iteration delay.
|
|
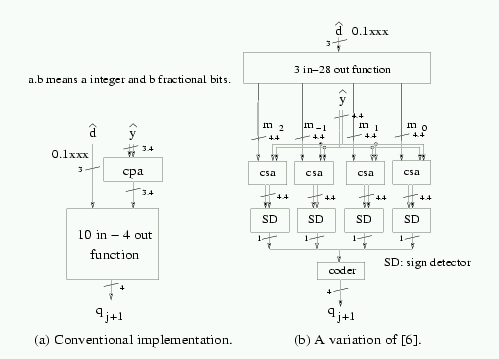 |
Recently [6] a scheme was described to implement the quotient-digit selection by preloading the selection constants corresponding to [^d] (which does not change for the whole operation) and performing the selection using comparisons (see Figure 2b3). Specifically, the algorithm consists in
Preloading the selection constants. Let us call the preloaded constants4 mk.
Perform the comparison in two steps:
produce zk = [^y] - mk. This subtraction is done with redundant adders.
perform the comparison by a sign detection of zk.
Based on our synthesis results (see Section 4) this scheme does not produce a significant speed up as compared to the standard algorithm.
Specifically, since
|
| |||||||
|
| (1) |
The number of fractional bits of the various signals is as described by
expression (1). We now consider the number of integer bits, which corresponds to the maximum value of
|[^y] -mk|. Since,
|
|
|
This means that 4 integer bits are necessary for performing a correct sign comparison, i.e. one more than the number of integer bits required to represent [^y] in the "classical" algorithm.
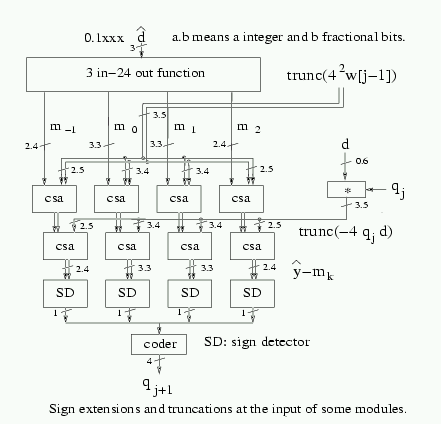
According to the discussion above, the number of bits of [^y]-mk is of four integer bits and four fractional bits, for a total of eight bits. We have performed a more detailed analysis to reduce this number to six. This reduction is based on the following considerations:
As shown in Table 1, for some ranges of values of [^y] some of the outputs of the SD modules are not used in the determination of the quotient digit. In the Table we denote by [L, H] the interval of values of [^y] and by x the dont cares. Note that the values of H, L, and mk depend on [^d].
| [^y] | SD2 | SD1 | SD0 | SD-1 | |
| [m2,H] | + | + | + | x | q = 2 if (SD2,SD1) = (+,+) |
| [m1,m2) | - | + | + | x | q = 1 if (SD2,SD1) = (-,+) |
| [m0,m1) | x | - | + | x | q = 0 if (SD1,SD0) = (-,+) |
| [m-1,m0) | x | - | - | + | q = -1 if (SD0,SD-1) = (-,+) |
| [L,m-1) | x | - | - | - | q = -2 if (SD0,SD-1) = (-,-) |
| [^y]-mk | [m1-m2, | [L-m1, | [L-m0, | [L-m-1, | |
| H-m2] | H-m1] | H-m0] | m0-m-1] | ||
| max(|[^y]-mk|) | 1.25 | 3.25 | 3.125 | 1.312 | |
| Integer bits | 2 | 3 | 3 | 2 |
With respect ot the number of fractional bits:
| k | -1 | 0 | 1 | 2 |
| Integer + fractional= total | 2+4=6 | 3+3=6 | 3+3=6 | 2+4=6 |
In summary, Table 2 gives the required number of integer and fractional bits of [^y]-mk.
 |
The iterations described in the previous section are executed either by a combinational network (if all iterations are unfolded) or by a sequential system, in which a part is executed each cycle. We consider this second approach, for the case where one iteration is performed per cycle.
The corresponding sequential system requires the introduction of registers that store the state between cycles. The placement of these registers has an effect on the minimum cycle time and on the area and energy of the implementation. We describe now a method to analyze the cycle time for the particular algorithm of the previous section.
The process begins with a dependency graph of the algorithm. In Figure 4(a) we show this graph for two iterations6, so that we can place the registers that define a complete cycle. We place registers in both iterations, but the corresponding registers of both iterations are implemented as a single register in the sequential system. To simplify the description of the analysis, we label the nodes A to F, resulting in the graph of Figure 4(b).
 |
In the graph we identify four paths labeled P1 to P4. To produce a sequential system we have to introduce registers to cut these paths, once per iteration. Consequently, a maximum of four registers are needed. However, we see that the paths are not disjoint, so that one register can be used to cut more than one path. In this particular algorithm, paths P1 and P3 intersect at node E and paths P2 and P4 at node F. Therefore, there are the following four possibilities in the placement of registers:
Now we consider the cycle time7. The minimum value is obtained by the maximum delay of all the paths between registers of the two iterations. Consequently, the minimum cycle time is obtained by minimizing this maximum delay.
A lower bound on the cycle time is given by the total length of the paths divided by two (since there are two iterations). We obtain
|
Note that the second and third components of this expression have the same value.
However, this bound cannot be always achieved, because of the restrictions on the placement of registers.
For reduced hardware complexity we restrict the discussion to the two-registers case. We now perform an analysis to obtain the conditions for minimum cycle time. We consider the possibility of partitioning the nodes and placing the register between these partitions. However due to the characteristics of each of the nodes, the partition is not convenient for all of them. The following considerations should be taken into account
With these considerations we have the following paths between registers:
At this point we can discard Path R2 ® R2 as critical, since it is composed only of two half adders. Therefore the problem consists in finding F2 (and then F1 ) so that the maximum of Path R1 ® R1, Path R1 ® R2 and Path R2 ® R1 is minimized. Since Path R1 ® R1 does not depend on F1 nor F2 , we try first to minimize the maximum of Paths R1 ® R2 and R2 ® R1.
Path R1 ® R2 is a increasing function of F2 and Path R2 ® R1 is a decreasing function with the same variable. Therefore the minimum of the maximum of Paths R1 ® R2 and R2 ® R1 is obtained when Path R1 ® R2=Path R2 ® R1. Using this condition we obtain
|
and then
|
Note that F is composed of a half adder and the sign-detector-and-coder and that it is convenient to place the flip-flops so that the half adder is not partitioned. If F2 > tSDc it might be necessary to place the flip-flops inside the half adder to optimize the path. However this condition is satisfied only if tSDc+twm < 3tha which seems not to be true for practical implementations.
The critical path is max(Path R1 ® R1, Path R1 ® R2 = Path R2 ® R1) , that is
|
We now describe the complete algorithm for radix 4 and quotient-digit set {-2,-1,0,1,2}.
The standard initial values are w[0] = 2-2x (to assure w[0] Ł (2/3)d) and q[0] = 0. Since this produces 2-2q, an additional iteration is required. The actual initialization depends on the location of registers (since these have to be initialized). For the two-register case, one possibility is
w[-1] = 2-4x
q0 = 0 (this requires that the register, which does not contain necessarily the qj value8, should be initialized so that q0 = 0 is produced).
After this initialization, the first iteration produces w[0] = 2-2x and q1 (or the value associated with q1 in the corresponding register).
To obtain the quotient of n radix-4 digits (including the rounding bit), it is necessary to compute n+1 digits (since, because of the initialization, the algorithm produces 2-2q). At the end of n+1 iterations, one register contains w[n] and the other register a value ässociated" with qn+1. After that it is necessary to
Obtain qn+1 and the last residual w[n+1] ( one cycle)
Detect sign of residual, correct quotient, normalize, and round (one cycle).
The total number of cycles is then n+3. This number of cycles is the same as for the other retimed schemes.
In this section we estimate the execution time to obtain a normalized rounded quotient of 53 bits (double precision) using the proposed implementation of the selection function and compare it with previous radix-4 implementations. We also estimate and compare the cell areas.
For this estimate we have used a 0.35 mm standard-cells library with power supply of 3.3 V and Synopsys analysis and synthesis tools (Design Analyzer). We performed the estimation pre-layout, therefore, we do not take into account the additional delay due to the actual parasitic capacitance of interconnections. To make the estimation as independent as possible from the technology we also give the delay using as unit the delay of an inverter loaded with four inverters; we call this unit tstd and it is 0.15 ns. for the library used.
As a first step we perform the timing of the recurrence. To do this, we use the delays of the modules9 indicated in Figure 4 and given in Table 3. Using the procedure described in the previous section10, we determine that the lower-bound of the cycle time (including register setup and propagation delay) is 2.40 ns and the registers should be placed as shown in the diagram of Figure 5.
| unit/gate | delay [ns] |
| half adder | 0.32 |
| sign detection and coding (6-bit) | 1.00 |
| wide mux (56-bit) | 0.86 |
| narrow mux (10-bit) | 0.56 |
| register (prop. delay) | 0.42 |
| register (set-up) | 0.10 |
To have a more reliable estimate we have done a global synthesis of the whole unit. In the synthesis of the part which computes the quotient digit, we lumped the short mux, the two levels of carry-save adders and the upper part of the sign-detector-and-coder (see Figure 3), into one block to optimize logic synthesis across the original blocks boundaries. The resulting cycle time is now 2.42 ns. (see Table 4). The slight increase with respect to the cycle time obtained using the delays of Table 3 is due to the actual loads. In this global implementation we obtained an area of about 4780 nand2 equivalent gates.
 |
Since the proposed algorithm requires (54/2)+3=30 cycles for double precision, the execution time is 73 ns. For the comparison, we synthesized the complete unit using the standard quotient-digit selection function and a variation of [6] using carry-save adders (Figures 2a and 2b). In these cases, the registers store directly w[j] and qj+1 since there is no advantage in other placements. Again for best use of the synthesis tool we lumped together the modules that compose the quotient-digit selection.
We obtained the cycle times reported in Table 4. From the table we conclude that the proposed implementation produces a speedup of about 1.35 and that the implementation of Figure 2b (variant of [6] using carry-save adders and retimed recurrence) produces a small speedup with respect to the basic implementation. The areas are roughly the same in all schemes.
| scheme | critical path | Tc [ns] | # tstd | speed-up | AREA | |
| basic | tREG+tnm+tHA+tCPA+tSEL+tsu | = | 3.25 | 22 | 1.00 | 4660 |
| (Fig. 2a) | ||||||
| variant of [6] | tREG+tnm+tHA+tCSA+tSDc+tsu | = | 3.10 | 21 | 1.05 | 4800 |
| (Fig. 2b) | ||||||
| proposed | tREG+tSDcl+tnm+tHA+tSDcu+tsu | = | 2.42 | 16 | 1.34 | 4780 |
| (Fig. 3) |
We have developed a scheme to reduce the cycle time of digit-recurrence division by retiming part of the quotient-digit selection so that it is not in the critical path. In addition, this modification allows the placement of the registers in a way to minimize the delay. Although the scheme has been developed for a general radix, all illustrations and evaluations have been done for radix 4. For this radix, we have estimated a speedup of about 35% with respect to the basic implementation and about a 30% with respect to the variation described in [6]. A natural extension would be to develop the details for higher radices.
We have only considered division but, as for the standard implementation, it can be combined with a similar scheme for square root.
1Research of E. Antelo is partially supported by the Xunta de Galicia under project PGIDT99XI20601A and of T. Lang by UC MICRO Grant 01-047.
2This scheme is similar to the use of truncated multiples of the divisor, but the use of selection constants as comparison points gives more flexibility, which is reflected in a somewhat simpler implementation.
3Actually the scheme proposed in [6] was implemented in standard non retimed recurrence.
4That is, the set of constants mk are obtained from the set mi,k for the value of i corresponding to the actual divisor.
5ëa űt means truncation of a to t fractional bits.
6The full adders have been divided into two half adders so as to have a finer granularity in the timing analysis.
7We do not include the register delay or set-up times at this point since these do not affect the placement of registers
8Because of the placement of registers, as discussed in Section 3.1
9These delays have been obtained by loading each module output with four inverters.
10We consider the two-register case since this achieves the bound of the critical path.